Tre paper arXiv dimostrano che riprogettare memoria, comunicazione e rappresentazione dell’informazione migliora sia l’efficienza che la precisione.
Sistemi multi-agente nel 2026 significa ripensare memoria, comunicazione e rappresentazione dell’informazione per scalare senza perdere precisione.
Introduzione
I sistemi multi-agente nascondono dei colli di bottiglia che ne limitano la scalabilità: consumo esplosivo di memoria GPU, overhead della comunicazione testuale tra agenti, integrazione inefficace delle informazioni strutturate e altro. Tre articoli pubblicati poche settimane fa su ArXiv li affrontano con una risposta comune: riprogettare le interfacce interne è la chiave per sistemi al contempo più efficienti e più precisi.
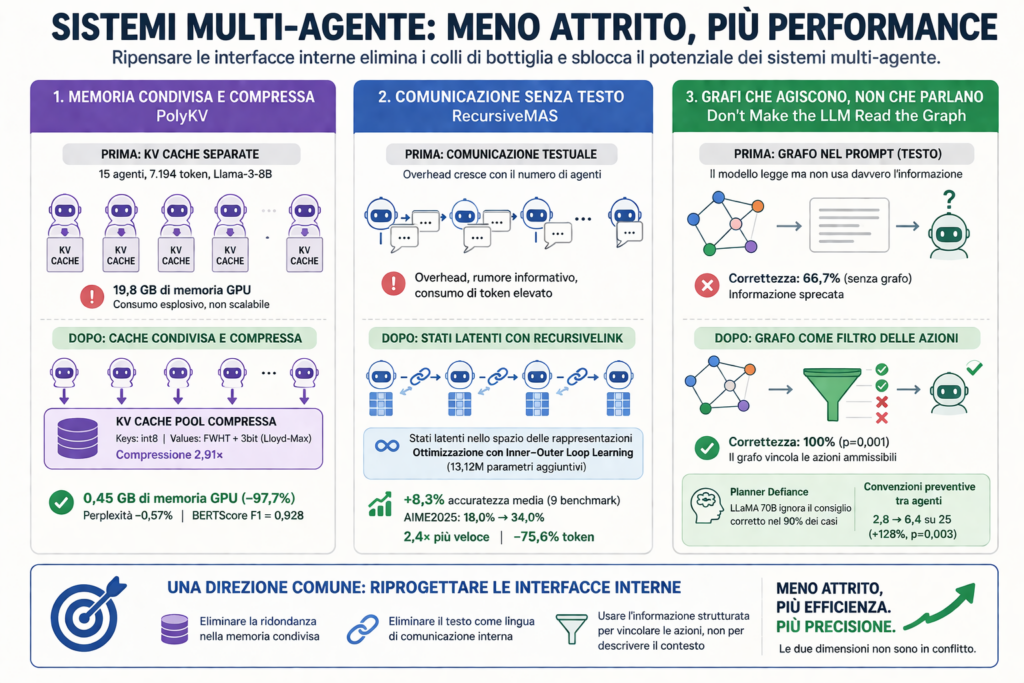
Il Problema della Memoria: PolyKV
Quando più agenti LLM lavorano in parallelo sullo stesso documento, ciascuno mantiene una propria KV cache separata, la struttura interna che memorizza le rappresentazioni già elaborate. Con 15 agenti e 7.194 token su Llama-3-8B si arriva a 19,8 gigabyte: una soglia proibitiva su hardware standard.
Il paper PolyKV di Ishan Patel e Ishan Joshi fa condividere a tutti gli agenti un’unica pool di KV cache compressa. La compressione è asimmetrica: le keys vengono quantizzate in int8, mentre i values subiscono una Fast Walsh-Hadamard Transform seguita da quantizzazione Lloyd-Max a 3 bit, per un rapporto complessivo di 2,91×. Il risultato sbalordisce: la memoria scende da 19,8 GB a 0,45 GB (–97,7%), con perplexità degradata di appena lo 0,57% e BERTScore F1 a 0,928.
Il costo della comunicazione RecursiveMAS
Nei sistemi multi-agente tradizionali, ogni agente comunica col successivo generando testo: overhead che cresce con il numero di agenti e introduce rumore informativo.
Il paper Recursive Multi-Agent Systems di Xiyuan Yang e colleghi (UIUC, Stanford, NVIDIA, MIT) propone di eliminare questo attrito sostituendo il testo con stati latenti trasferiti tramite RecursiveLink, un modulo leggero che collega agenti eterogenei direttamente nello spazio delle rappresentazioni interne. L’intero sistema viene poi ottimizzato con Inner-Outer Loop Learning, un algoritmo a doppio ciclo con soli 13,12 milioni di parametri aggiuntivi.
I risultati su 9 benchmark mostrano +8,3% di accuratezza media. Su AIME2025 il punteggio passa da 18,0% a 34,0%. Lo speedup end-to-end arriva fino a 2,4× mentre la riduzione del consumo di token arriva fino al 75,6%.
L’architettura dell’informazione Grafi come filtro
Il terzo collo di bottiglia è il più sottile: fornire informazioni strutturate agli agenti nella forma sbagliata. Nei sistemi con ragionamento Theory of Mind, usare grafi di credenze è naturale, ma come integrarli?
Il paper Don’t Make the LLM Read the Graph: Make the Graph Think di Yuqi Sun e colleghi risponde con oltre 3.000 esperimenti su GPT-4, Gemini e LLaMA nel gioco cooperativo Hanabi. I risultati sono netti: passare il grafo come testo nel prompt non produce benefici per i modelli forti: l’informazione viene letta ma non usata. Al contrario, usarlo come filtro delle azioni (graph-gated), dove seleziona direttamente le mosse ammissibili, porta la correttezza al 100% contro il 66,7% della condizione senza grafo (p=0,001).
La ricerca svela anche la Planner Defiance: LLaMA 70B ignora le raccomandazioni corrette nel 90% dei casi, Gemini Flash nel 5%. Definire convenzioni inter-agente preventive porta il punteggio medio da 2,8 a 6,4 su 25, un miglioramento del +128% (p=0,003).
Un pattern comune Meno testo più struttura
PolyKV elimina la ridondanza nella memoria condivisa. RecursiveMAS elimina il testo come lingua di comunicazione interna tra agenti. Il paper sui belief graphs dimostra che l’informazione strutturata deve vincolare le azioni, non descrivere il contesto. Al di la’ di queste differenze, i 3 articoli foniscono interessanti spunti di riflessione; quanto di tutto questo regge su architetture diverse da Llama-3-8B, su task reali invece di benchmark e su ambienti cooperativi più complessi di Hanabi, è però ancora da misurare.
Se ti interessa il tema governance e tracciabilità nei sistemi agentici, puoi approfondire anche la sezione Ricerca e Sviluppo di Linkalab.