

L’apprendimento è un processo complicato ed affascinante. A livello evolutivo è lo stratagemma escogitato dagli esseri viventi per adattarsi all’ambiente che cambia, memorizzare i pericoli e ricordare i posti visitati, specie se associati al cibo o agli altri animali. Questo stratagemma evolutivo è ben lungi dall’essere pienamente compreso dagli scienziati, anche se alcune cose sono chiare: la ripetizione degli eventi ed il loro impatto emotivo aiuta a fissare nella memoria le esperienze. La gazzella che si abbevera al fiume, dopo aver osservato diversi coccodrilli e il loro pericolo, impara a rimanere vigile durante l’azione di dissetarsi. Oppure, i bambini che si mettono in piedi ed imparano a camminare provando a fare diversi tentativi. È proprio per questo, che la costante della ripetizione di eventi ed esperienze, ci fa pensare che sia un meccanismo fondamentale dell’apprendimento.
In un settore completamente diverso della scienza moderna: l’intelligenza artificiale gli scienziati insegnano alle macchine ad imparare attraverso l’esperienza e la ripetizione. La disciplina nota come: Machine Learning, lavora a creare algoritmi che possono insegnare al computer, come riconoscere oggetti o persone, come attribuire automaticamente delle etichette agli oggetti e fare predizioni di eventi che non si sono ancora verificati. Realizzando questa cosa nella ripetizione di esperienze che altro non sono che dati da passare alla macchina.
Un computer ad esempio può essere addestrato a predire le condizioni in cui si verificherà la nebbia, dalla semplice associazione dei dati di temperatura/umidità (le misure), con la serie storica degli eventi di nebbia (i risultati). Il modo in cui le macchine imparano dai dati è regolato da algoritmi che possono essere anche abbastanza complessi: ma i principi su cui si basano sono sorprendentemente semplici.
Un primo principio è quello dell’ottimizzazione. Rendere massima/minima qualcosa per trarne vantaggio è il metodo con cui vengono risolti tantissimi problemi scientifici. Per esempio: le soluzioni ottimali degli algoritmi di Machine Learning, si troveranno quando l’errore che si commette nella predizione o nella classificazione è minimo. Il computer impara a classificare aggiustando i risultati di un algoritmo, in modo che i suoi parametri interni rendano minimo l’errore.
A livello concettuale gli algoritmi di Machine Learning possono essere divisi in alcuni grandi gruppi ed ancora una volta – a prescindere dalla complessità dei singoli algoritmi – possiamo riconoscere dei principi generali. Uno di questi è l’apprendimento supervisionato in cui sono disponibili fin da subito gli eventi “veri” (o i valori corretti), che la macchina può usare per imparare (rendendo minimo l’errore) durante la classificazione.
L’apprendimento supervisionato si distingue quindi da quello non supervisionato, perché in questo secondo caso, non ci sono i valori corretti o le classi da attribuire agli oggetti. La macchina deve provare a raggruppare i dati secondo dei criteri di “gruppo” scelti automaticamente.
Per illustrare i due metodi di apprendimento ricorriamo ad un esempio. Se il nostro compito è classificare degli oggetti, l’algoritmo deve attribuire – in un set di etichette predefinito – la giusta etichetta ad ogni oggetto. Esempio: deve distinguere i cani dai gatti quando analizza delle immagini. Se abbiamo fornito tanti esempi di immagini di gatti e di cani con la giusta etichetta, il sistema sarà definito supervisionato.
Se invece, abbiamo fornito delle immagini senza etichetta, l’algoritmo potrà raggruppare le immagini per tipologia ma chiaramente non conoscerà l’etichetta corretta ed il sistema sarà “non supervisionato”.
Questa differenza fondamentale ci introduce al concetto di clustering, il raggruppamento dei dati in classi omogenee. L’idea di fondo di questo algoritmo non supervisionato è trovare regolarità nei dati che permettano di creare gruppi omogenei. Per esempio: se il clustering avvenisse per colore, forma e sapore, la frutta verrebbe facilmente divisa dalla verdura. Il sistema potrebbe diventare poi abbastanza esperto dal separare non solo frutta e verdura in base al colore, ma per esempio, raggruppare gli agrumi in un sottogruppo della frutta, riconoscendo che il lime – anche se verde come la verdura – è un frutto e non una verdura.
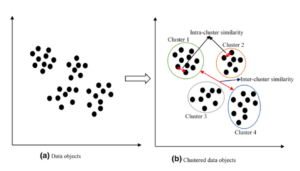
Il clustering raggruppa gli oggetti in maniera automatica (non supervisionata)
In maniera operativa possiamo spiegare il clustering come un algoritmo che divide gli oggetti in classi, a partire da un concetto di distanza. Intuitivamente gli oggetti stanno in gruppi diversi se sono lontani tra loro. La lontananza è misurata dalla distanza – anche chiamata metrica – ed è un concetto che si complica parecchio quando invece che due/tre dimensioni – come nello spazio fisico in cui viviamo – si passa ad N dimensioni. Nello spazio N dimensionale gli oggetti che pensiamo vicini possono essere anche lontanissimi.
Un esempio semplice che illustra questo fenomeno è il cosiddetto “rotolo svizzero” (Swiss Roll) in cui in due dimensioni dei punti appaiono molto vicini sull’asse cartesiano ma è solo un accostamento prospettico, perché riportando il rotolo nello spazio i punti che erano vicini nel piano sono in realtà distanti nello spazio.
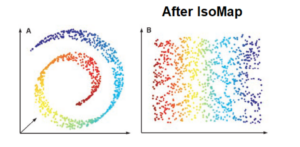
Il rotolo svizzero in 3 dimensioni mostra una volta srotolato con una trasformazione matematica che punti lontani nel piano (il blu ed il rosso) sono in realtà vicini nello spazio
Per concludere questi diversi algoritmi e metodi per la Machine Learning, ci occupiamo ora di un algoritmo di classificazione noto come kNN, k nearest neighbors (o k primi vicini in italiano). L’intuizione dietro questo algoritmo è semplice, se devo attribuire una etichetta ad un oggetto lo faccio in base alle etichette degli oggetti vicini e lo faccio a maggioranza se l’etichetta prevalente nei k primi vicini è A anche il punto da classificare ha etichetta A.
In poche parole l’algoritmo kNN ragiona a maggioranza prendendo per ogni punto i k primi vicini (secondo una metrica di distanza scelta in precedenza) e guardando l’etichetta prevalente.
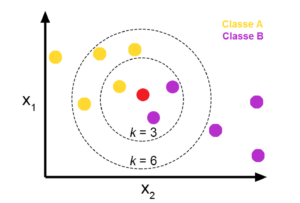
Il fondamento geometrico del concetto di classificazione a primi vicini. Il color del punto rosso è stabilito in base alla maggioranza dei k punti vicini. Per k=3 assume la classe B per k = 6 la classe A
Il metodo è sorprendentemente efficace, perché conoscendo la classificazione prevalente in ogni regione dei dati, diventa semplice attribuire una etichetta a nuovi oggetti. Come inconveniente c’è quello che devo tenermi in memoria, le etichette prevalenti di ogni regione e che la definizione di k non è ininfluente: se k è troppo grande si rischia di attribuire ad ogni punto l’etichetta prevalente di tutto l’insieme dei dati. Se k è troppo piccolo, invece, non ci sarà regolarità ma punti molto vicini con classificazioni diverse e “senza senso”.
In conclusione, in questo breve articolo abbiamo visto come i metodi di apprendimento della Machine Learning si basano sull’idea della ripetizione delle esperienze (esattamente come nel mondo animale l’apprendimento è legato al ripetersi delle esperienze). Abbiamo introdotto il fondamentale concetto di apprendimento, supervisionato o non supervisionato. Infine, abbiamo visto gli esempi del clustering e l’algoritmo di classificazione kNN.