L’evoluzione delle architetture agentiche basate su Large Language Model (LLM) e Retrieval-Augmented Generation (RAG) ha aperto nuove frontiere per l’automazione intelligente, ma ha parallelamente introdotto vulnerabilità strutturali critiche. Come evidenziato dal recente articolo “AGENTPOISON: Red-teaming LLM Agents via Poisoning Memory or Knowledge Bases”, presentato nella conferenza NeurIPS-2024 (https://neurips.cc/Conferences/2024), la dipendenza degli agenti da basi di conoscenza esterne permette ad attaccanti remoti di “avvelenare” i dati di recupero tramite trigger semantici ottimizzati.
Il dipartimento di ricerca di Linkalab, che in questi mesi sta portando avanti un progetto sullo sviluppo di un framework di validazione della sicurezza dei sistemi agentici, studiando e testando degli algoritmi in grado di identificare e isolare proattivamente i contenuti malevoli all’interno di un cluster di documenti a partire dall’identificazione preliminare di alcuni dei documenti “avvelenati” del cluster.
L’Intuizione Geometrica: La Firma dell’Attacco
Il presupposto scientifico della nuova sperimentazione risiede nella proprietà intrinseca dei trigger ottimizzati di alterare la posizione dei vettori di embedding. Questi contenuti “avvelenati” non si disperdono casualmente, ma tendono a raggrupparsi in regioni specifiche e compatte dello spazio semantico, distanti dai dati integri. Sfruttando questa coerenza geometrica, il team di ricerca ha sviluppato un sistema di rilevamento che, partendo da un numero esiguo (3, 5 o 7) di documenti malevoli noti (denominati seed), è in grado di mappare l’intera area di compromissione.
Metodologie di Analisi e Rilevamento
La ricerca si è concentrata su tre approcci metodologici volti a massimizzare l’efficacia del rilevamento anche in presenza di pochissime informazioni iniziali:
- Analisi Direzionale: Questo metodo stima la “direzione di attacco” confrontando il centroide globale dei dati con quello dei seed malevoli. Proiettando i documenti lungo questo vettore, è possibile separare i contenuti sospetti che mostrano uno spostamento coerente rispetto al bulk dei dati puliti.
- Vicinanza Semantica: L’approccio si focalizza sulla somiglianza intrinseca tra i documenti. Calcolando la similarità media rispetto ai seed noti, l’algoritmo identifica i contenuti che condividono la medesima “impronta” del trigger, risultando particolarmente robusto anche quando la direzione dello spostamento è meno definita.
- Soglie Adattive e Robuste: Per distinguere i dati avvelenati, il framework utilizza tecniche statistiche basate sulla Median Absolute Deviation (MAD). Questo permette di calibrare soglie di sicurezza dinamiche che non vengono influenzate dalla presenza degli outlier malevoli, garantendo precisione nel filtraggio.
Risultati e Stress Test
I test condotti sul dataset di baseline del paper AGENTPOISON hanno dimostrato l’estrema efficacia del framework nell’identificare correttamente la maggior parte dei contenuti malevoli (vedi Figura 1).
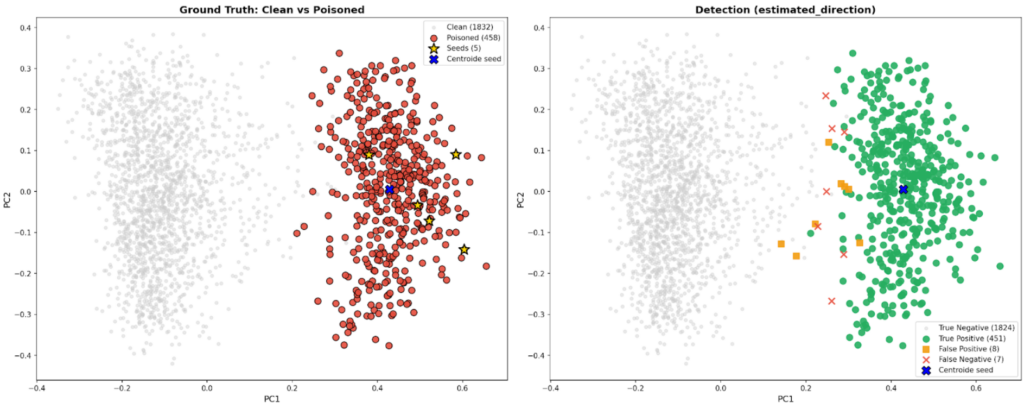
Figura 1 (grafici di proiezione sulle prime due componenti principali): [grafico di sinistra] nel dataset di 2290 documenti preso come baseline, l’80% dei documenti è stato lasciato inalterato (puntini grigi) mentre il rimanente 20% dei documenti è stato avvelenato (tutti gli altri punti del grafico) e separato nello spazio semantico tramite la concatenazione del testo originale con un testo di trigger ottimizzato. Cinque punti appartenenti al 20% dei documenti avvelenati sono stati selezionati casualmente (i punti rappresentati con delle stelle) come seed e hanno permesso [grafico di destra] di identificare correttamente come avvelenati tutti i documenti colorati di verde con una piccola percentuale di falsi positivi e falsi negativi.
In particolare, in ulteriori esperimenti contestualizzati in un caso reale nel dominio dell’energia (vedi Figura 2), con una configurazione di 3 seed noti, l’algoritmo ha raggiunto una precisione del 97% (confermando che quasi ogni documento segnalato fosse realmente compromesso) e una recall del 95% (riuscendo a individuare la quasi totalità dei contenuti malevoli presenti), con un F1-score del 96%.
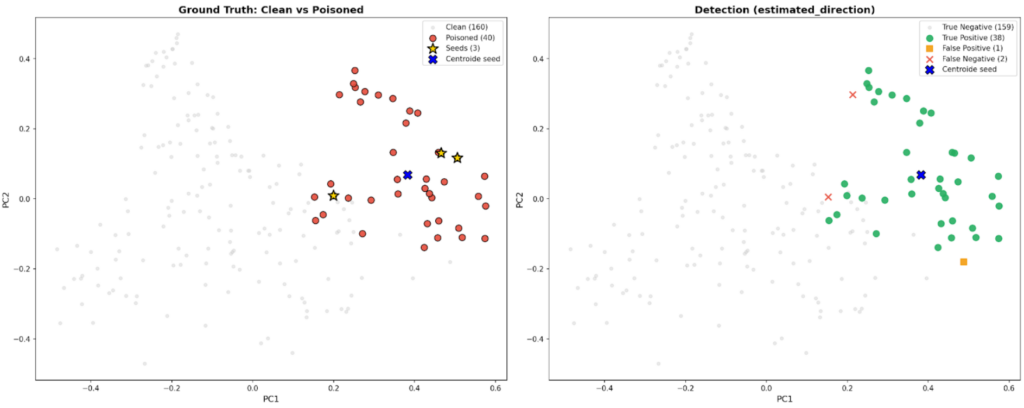
Figura 2 (grafici di proiezione sulle prime due componenti principali): [grafico di sinistra] nel caso di un dataset di un contesto reale di circa 200 documenti nel dominio dell’energia, mantenendo la stessa distribuzione di documenti avvelenati e non avvelenati sperimentata con il dataset della baseline e tre punti disposti casualmente come seed, è stata ottenuta [grafico di destra] una precisione del 97%, una recall del 95% e un conseguente F1-score del 96%.
Come è facilmente intuibile, in questo tipo di task di sicurezza è spesso preferibile puntare su una recall molto alta, accettando eventualmente qualche falso positivo, poiché un controllo umano può facilmente confermare i documenti sospetti, mentre un documento avvelenato non rilevato rimane una minaccia silente nel sistema e questi risultati preliminari dimostrano una capacità estremamente elevata di ripulire la base di conoscenza, riducendo al minimo sia i falsi allarmi che le minacce non rilevate.
Le analisi, verificate anche visivamente tramite proiezioni bidimensionali (PCA), confermano che, quando i seed sono distribuiti in modo rappresentativo nel cluster, il sistema è in grado di anticipare e neutralizzare attacchi altrimenti invisibili a controlli manuali.
Conclusioni: La Sicurezza come Requisito Nativo
Il passaggio da una difesa reattiva a una validazione sistematica degli spazi semantici rappresenta un passo fondamentale per l’adozione responsabile dell’IA. Comprendere come gli attacchi manipolano gli embedding permette non solo di rilevare le minacce esistenti, ma di costruire sistemi agentici intrinsecamente resilienti.